
You might not like to admit it, but you’re related to me.
It’s very unlikely that you’re my sibling (I’m not even sure if my family read these posts). You’re one of over seven billion people alive today, and I have only one sister, so the chance that you as a random person are my sibling is < 1 in a billion. You're not my first cousin, because (as far as I know) I dont have any first cousins. But further back than that it all starts it go a bit hazy. I have eight great-grandparents and I vaguely know their names and know some of their descendants, I'm guessing you're not one of them (I met some of my 2nd cousins once at a Christmas long ago). But how far do I have to go back till I find I'm related to you? I have sixteen great-great grandparents, I have no clue who they were, and I certainly have no clue who my third cousins are. My number of ancestors doubles every generation I go back, as does yours. And my awareness of who these ancestors were, and my distant cousins, drops even more quickly.
Our numbers of ancestors grow so quickly that it is soon unavoidable that we have shared ancestors. Six hundred years ago (roughly 20 generations back) I'll have just over a million ancestors alive (220), a thousand years back I potentially have over a billion ancestors alive (233). There simply aren’t that many people alive in Europe back then, and so I’m a descendant of everyone who lived then as long as they left descendants (and vast numbers did). So I’m related to everyone famous who lived back then, and everyone non-famous as well. If you have European ancestry, you’ll be related to them all too, and we’ll be distant cousins.
To illustrate this idea consider the following computer simulation. Let’s think of a constant size population of one hundred thousand people. I’m in the present (the red dot), Each generation back my ancestors are drawn at random from the one hundred thousand people. Just for display purposes, I’ve arrayed the hundred thousand people out on a horizontal line, representing the population. Each generation back I draw lines from my ancestors in that generation to my ancestors one further generation back. You can see the lines tracing from my parents, to my four grandparents, and so on. The number of lineages of my family tree that we’re tracing quickly gets mindboggling, and we cant see individual connections anymore.
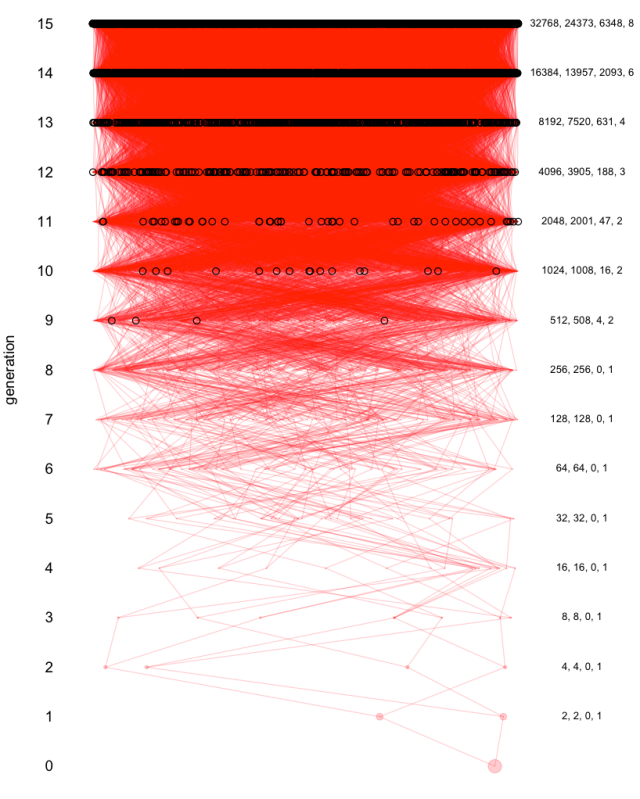
Every time an ancestor appears more than once in my simulated pedigree I draw a circle around them. I’ve kept track of (left to right) my number of unique ancestors in each generation, the number of ancestors that are present more than once in my pedigree, and the maximum number of times an individual appears in my pedigree. My first overlapping ancestors occurs nine generations back; I should have 512 ancestors, but I have 508 ancestors instead. Four individuals are circled, each of them are my great7 grandparents twice over (technically these are called inbreeding loops). I can trace back multiple routes through my pedigree which lead to each of these ancestors. By fifteen generations back I should have over thirty two thousand ancestors, but in fact I only have less than twenty five thousand ancestors, there’s roughly six thousand individuals who appear in my pedigree more than once in that generation. One of them appears several times over. My pedigree is collapsing in on itself.
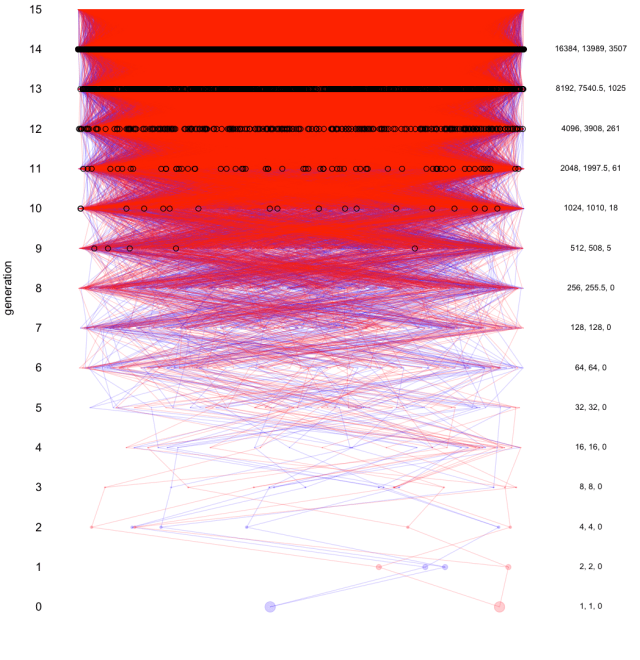
Now lets think about the overlap between our family trees. I’ve drawn your (simulated) pedigree back in blue, with mine overlain. When I find an individual who is a new genealogical ancestor to both of us I draw a circle around them. I keep track of the number of shared ancestors (the rightmost number, the other two give 2k and the mean actual number of ancestors a modern individual has). We don’t have to go very far back to find that our family start to overlap.
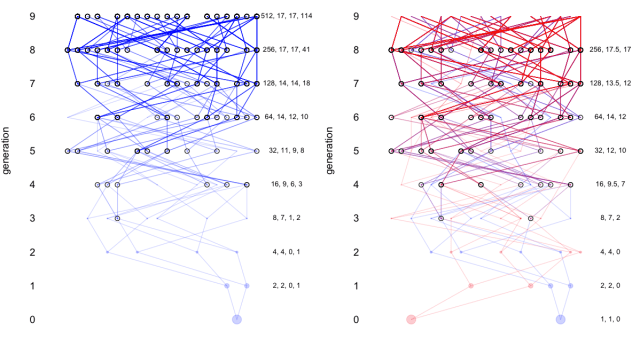
It’s also fun to do these simulations with small population sizes (see below). Here I do them, with only 20 individuals. Obviously this population size is pretty unrealistic, but it does allow you to see the overlap in the pedigrees more clearly.
The pedigree collapse problem has been highlighted by many people over the years, both for real pedigrees and through mathematical models. A good popular account of pedigree collapse is found in the New Yorker article the Mountain of Names (and the book of the same name). Also Carl Zimmer and in Adam Rutherford’s book both have great accounts of these ideas, and their genetic implications. There’s a nice article on the math underlying pedigree collapse by Wachter, describe the number of unique ancestors of person of British ancestry at the Norman Conquest (I’ve posted a [bad] pdf of the chapter here).
Chang extended these ideas and explored how far back we have to go to find the first common genealogical ancestor of the entire population, i.e. the first individual who all of our family trees trace back to, in a well mixed population of size N individuals. He found that we should expect to find the common ancestor of the entire population roughly log2(N) generations in the past, and that there’s little randomness in this result (i.e. if we run the process multiple times we get very similar answer). The math of this is somewhat involved, but intuitively the answer depends on the logarithm of the population size in base two, because you number of ancestors grows as 2k, so number of ancestors will be roughly the population size when 2k=N, which we can rearrange to find that the critical time should be roughly k=log2(N) generations in the past. He showed that (in a well mixed) population with N individuals, we only have to go 1.77 log2(N) generations in the past to find the time when everyone in the population (who left descendants) is an ancestor to the entire population.
Rhoade, Olsen, and Chang showed that even considering the low levels of migration among world-wide populations you only have to go back a few thousand years to find the first common genealogical ancestor of all humans. And we dont have to go much further back in time to find that everyone in the world (who left descendants) is an ancestor of everyone in the present. Even quite high levels of inbreeding make little difference to these results (see Lachance’s paper). This idea is wild to think about, we’re all descended from everyone in the world (who has descendants) more than a few thousand years back. Your family tree is vast and vastly messy, no one is descended from just one group of people.
A range of other people have worked on this problem. Notably Derrida, Manrubia, and Zanette have studied the number of times ancestors in pedigrees in mathematical models (see also their followup paper). They also showed that roughly 80% of individuals in a given generation (further in past than the cut off given by Chang) can expect to be ancestors of the entire population today. And Manrubia, Derrida, and Zanette have also written a nice, reasonably accessible account of many of these results and more.
In the next post we’ll turn what this implies about how genetically related we are to other people. We’ll address why, even though we are all very closely related, we aren’t genetically identical to each other. We’ll see, somewhat paradoxically, that some of the differences among humans, even within populations, are millions of years old. We’ll talk about why, even though we all have Neanderthal ancestors only some of us carry traces of Neanderthal ancestry in our genomes.
The code for these plots is on github here. I wrote the code, and most of this blog post, over a couple of our toddler’s naps while sat in a gravel pullout by a lake (he only naps in the car). It’s a nice lake, see the pic below, but I get some funny looks from cyclists as they bike past and watch me typing. This is all the say, that the code and blogpost are quickly (and somewhat poorly) written.


Reblogged this on Shane O'Mara.
Brilliant! Thoroughly enjoyed reading this. My great great grandfather was the penultimate king of Portugal and, as all royalty are related (inbred!) it was easy for me to find so, so many overlaps on my family tree. Thanks for this, it’s great 👍
Thank you for including the photo of your view, and the story of your nap-based working hours. I’m always inspired to hear about how people work around having toddlers!
I read just about everything you published and it was very interesting for about 3 hours and then I started feeling like it was so variable dependent that it felt an act of futility.
Terrific, Graham! I am currently reading through your inspirational “genetic genealogy” blogs here and find them spookily aligned with my interests. I hope to come back with some particular comment in due course. For now, I would just like to draw the attention of you and your readers to my newly-released paper https://www.researchgate.net/publication/323757098_How_many_ancestors_does_a_Briton_have
It estimate ancestors in each generation, cousins of any degree and the “coefficient of inbreeding” using original methods. Please take a look and leave your comments/questions on ResearchGate or here.
Reply